TensorFlowチュートリアルの自然言語処理系ラストのセクションは
SyntaxNet の説明だがTensorFlowサイト自体にはほとんど情報がなく、
GitHubリンクに丸投げになっている。
なので
[GitHub] SyntaxNet: Neural Models of Syntax.
のトップページドキュメントREADME.mdを翻訳してみた。
実はこれまで翻訳は Yahoo 翻訳 を使っていたのだけど、
最近Google翻訳がすんごく良くなったという記事を読んだので
今回はGoogle翻訳したものを修正するという方法でやってみました。
以下、貼り付けますが、勝手翻訳にはかわりないので
参照するかたは At your own risk でお願いします。
-------
SyntaxNet: 文法のニューラルモデル
Andor et al.(2016) にて解説されているモデルのTensorFlow実装です。アップデート :Parsey モデルは、Universal Dependency データセットで訓練された 40 の言語で利用可能になりました。テキストセグメンテーションと形態素解析がサポートされています。
Googleでは、人間の言葉を知的な方法で処理するために、コンピュータシステムがどのように人間の言葉を読んで理解することができるかについて、多くの時間を費やしています。 自然言語理解(NLU)システムの基盤となる TensorFlow のオープンソースニューラルネットワークフレームワークである SyntaxNet を公開することにより、私たちの研究成果をより広範なコミュニティと共有することができます。 私たちのリリースには、独自のデータで新しい SyntaxNet モデルを訓練するために必要なすべてのコードと、訓練した英語パーザ Parsey McParseface と、英語のテキストを分析するために使用できるコードが含まれています。
Parsey McParseface はどれくらい正確ですか? 今回のリリースでは、1台のマシン(たとえば、現代のデスクトップで約600ワード/秒)で使用するのに十分速く動作するモデルと、利用可能な最も正確なパーサーであるモデルのバランスを取ってみました。 Parsey McParseface がいくつかの異なる英語ドメインの学術文献と比較する方法は次のとおりです(すべての数字は、ツリー内の正確な頭割り当てまたはラベル付けされていない添付ファイルのスコアです)。
| モデル | ニュース | Web | 質問 |
|---|---|---|---|
| Martins et al. (2013)" | 93.10 | 88.23 | 94.21 |
| Zhang and McDonald (2014)" | 93.32 | 88.65 | 93.37 |
| Weiss et al. (2015) | 93.91 | 89.29 | 94.17 |
| Andor et al. (2016)* | 94.44 | 90.17 | 95.40 |
| Parsey McParseface | 94.15 | 89.08 | 94.77 |
Parsey McParsefaceは最先端の技術であることがわかります。 さらに重要なことに、SyntaxNetを使用すると、正確さをさらに追求したい場合、隠れたユニットと大きなビームサイズを持つより大きなネットワークを訓練することができます: Andor et al。 (2016)* は、ビームとネットワークが大きい単純なSyntaxNetモデルです。 データセットの詳細については、"Treebank Union"セクションにある論文を参照してください。
Parsey McParseface は、品詞(POS)タグ付けのための最先端技術です(以下の数字はトークン単位の精度です)。
| モデル | ニュース | Web | 質問 |
|---|---|---|---|
| Ling et al. (2015) | 97.44 | 94.03 | 96.18 |
| Andor et al. (2016)* | 97.77 | 94.80 | 96.86 |
| Parsey McParseface | 97.52 | 94.24 | 96.45 |
このチュートリアルの最初の部分では、必要なツールをインストールし、このリリースで提供されているすでに訓練されたモデルを使用する方法について説明します。 チュートリアルの第2部では、モデルに関する詳細な背景と、他のデータセットでモデルをトレーニングするための手順を説明します。
インストール
SyntaxNet モデルを実行するには、パッケージをソースからビルドする必要があります。 以下のものがインストールするには必要です:
- python 2.7:
- python 3 はまだサポートされていません
- pip (python パッケージマネジャ)
- Ubuntuの場合は、 apt-get install python-pip を実行
- brew は OSX上のpythonと一緒に pip をインストールします
- bazel :
- バージョン 0.3.0 - 0.3.1
- インストラクションは こちら
- もしくは、 bazel <./dev> を実行してシステムに合わせて https://github.com/bazelbuild/bazel/releases からダウンロード
- コマンド sudo dpkg -i <.deb file> を使ってインストール
- bazel version とタイプして bazel バージョンを確認
- swig:
- Ubuntuの場合、 apt-get install swig を実行
- OSXの場合、 brew install swig を実行
- TensorFlowによりサポートされているバージョンの protocol buffers :
- pip freeze | grep protobuf を実行して protobuf バージョンを確認
- pip install -U protobuf==3.0.0b2 を実行してサポートされているバージョンへ更新
- asciitree :デモの際にコンソール上にパースツリーを描画のため
- pip install asciitree
- numpy :科学技術計算のためのパッケージ
- pip install numpy
- mock :UTのためのパッケージ:
- pip install mock
上記の手順を完了したら、次のコマンドでSyntaxNetをビルドしテストすることが可能です。
git clone --recursive https://github.com/tensorflow/models.git
cd models/syntaxnet/tensorflow
./configure
cd ..
bazel test syntaxnet/... util/utf8/...
# Macの場合、次のコマンドを実行:
bazel test --linkopt=-headerpad_max_install_names \
syntaxnet/... util/utf8/...
Bazelは、渡されたすべてのテストの報告を完了する必要があります。
この Dockerfile を使用して Docker コンテナ内の SyntaxNet をコンパイルすることもできます。
GPUをサポートする SyntaxNet を構築するには、issue/248 の手順を参照してください。
注意 :OSXでDockerを実行している場合は、Docker VMに十分なメモリが割り当てられていることを確認してください。
初めての開始
SyntaxNetを正常に構築すると、構文ネット/モデルの下にある Parsey McParseface ですぐにテキストの解析を開始できます。 最も簡単なのは、含まれているスクリプト syntaxnet/demo.sh を使用または変更することです。このスクリプトは、プレーンテキストを入力として解析するための基本的な設定を示しています。
標準入力からのパース
syntaxnet/demo.sh のスクリプトに、1行のテキストにつき1つの文を渡すだけです。 スクリプトは、テキストを単語に分解し、POSタガーを実行し、パーサを実行してから、構文解析ツリーのASCIIバージョンを生成します。
echo 'Bob brought the pizza to Alice.' | syntaxnet/demo.sh
Input: Bob brought the pizza to Alice .
Parse:
brought VBD ROOT
+-- Bob NNP nsubj
+-- pizza NN dobj
| +-- the DT det
+-- to IN prep
| +-- Alice NNP pobj
+-- . . punct
ASCIIツリーは、チュートリアルのグラフで視覚化されたように、左から右にではなく、構文解析されたテキストを表示します。 この例では、 "brought"という動詞は、文のルートであり、主語 "Bob"、目的語 "pizza"、および前置詞句 "to Alice"であることがわかります。
トークン化されたCONLL形式のテキストをフィードとして使用する場合は、 demo.sh --conll を実行します。
コーパスをアノテート
特定のファイルを読み書きするようにパイプラインを変更するには(stdinとstdoutをパイプするのではなく)、 demo.shを修正して、希望するファイルを指すようにする必要があります。 SyntaxNet モデルは、実行時フラグ(変更が容易)とテキスト形式の TaskSpec プロトコルバッファの組み合わせによって構成されます。 デモで使用される spec ファイルは、syntaxnet/models/parsey_mcparseface/context.pbtxt 内にあります。
stdin/stdout の代わりに corpora を使用するには、次のことが必要です。
- TaskSpec 内の input フィールドを作成または変更し、希望する場所を指定する file_pattern を使用します。 入力コーパスが CONLL 形式の場合は、record_format: 'conll-sentence' を必ず入れてください。
- --input および/または --output フラグを変更して、stdin および stdout の代わりにリソースの名前をアウトプットとして使用します。
例えば、 POS タグに CONLL コーパス ./wsj.conll を付ける場合は、インプット用とアウトプット用の2つのエントリを作成します。
input {
name: 'wsj-data'
record_format: 'conll-sentence'
Part {
file_pattern: './wsj.conll'
}
}
input {
name: 'wsj-data-tagged'
record_format: 'conll-sentence'
Part {
file_pattern: './wsj-tagged.conll'
}
}
コマンドラインで --input=wsj-data --output=wsj-data-tagged を使用して、これらのファイルの読み書きを指定することができます。
Python スクリプトの構成
上記のように、Pythonスクリプトは2つの方法で設定されます:
- 実行時フラグ は、 TaskSpec ファイルを指し示し、読み書きのために入力を切り替え、さまざまな実行時モデルのパラメータを設定するために使用されます。 訓練時に、これらのフラグを使用して、学習率、隠れ層サイズ、およびその他の重要なパラメータを設定します。
- TaskSpec proto は、遷移システム、機能、およびパーサが必要とする名前付き静的リソースのセットに関する構成を格納します。 これは --task_context フラグで指定します。 覚えておくべき重要な注意事項:
- TaskSpec のパラメータ設定には、 brain_pos(タガーに適用)または brain_parser (パーサに適用)のどちらかの接頭辞があります。 --prefix 実行時フラグは、2つの構成からの読み込みを切り替えます。
- リソースは、複数の訓練段階で作成および/または変更されます。 前述のように、特定のファイルを読み書きするために、評価時にリソースを使用することもできます。 これらのリソースは、TensorFlow オペレーションの呼び出しを介して個別に保存され、 --model_path フラグを使用してロードされるモデルパラメータとは別個のものです。
- TaskSpec にはファイルパスが含まれているため、このファイルをコピーするだけでは訓練されたモデルを再配置することはできません。すべてのパスを移動して更新する必要があります。
一部の実行時フラグは、訓練とテスト(例えば、隠れユニットの数)の間で一貫している必要があることに注意してください。
次のステップ
このフレームワークを拡張するには多くの方法があります。 新しい機能の追加、モデル構造の変更、他の言語のトレーニングなどがあります。以下の詳細なチュートリアルを読んで、残りのフレームワークの機能を学習してください。
詳細なチュートリアル:SyntaxNet を使った NLP パイプラインのビルド
このチュートリアルでは、新しいモデルのトレーニング方法を説明し、モデルの NLP 側の技術的な詳細について説明します。 ここでの目標は、このパッケージで作成された NLP パイプラインについて説明することです。
データの取得
付属の英語パーサ、Parsey McParseface は、 Penn Treebank と OntoNotesの標準コーパスと English Web Treebank で訓練されましたが、残念ながら自由に利用できません。
しかし、 Universal Dependencies プロジェクトは、自由に利用可能なツリーバンクデータを複数の言語で提供しています。 SyntaxNet は、これらのコーパスのいずれかで訓練され評価されることができます。
品詞(POC:part-of-speech)タグ付け
その解釈に影響を与えるいくつかのあいまいさを示す次の文章を考えてみましょう。
I saw the man with glasses. (和訳:私は眼鏡で男を見た。)
この文は、単語で構成されます。グループに分かれた文字列(「I」、「saw」など)文中の各単語は、 _文法の機能_ を持ち、言語の意味を理解するのに役立ちます。たとえば、この例の「saw」は動詞「see」の過去の時制です。しかし、単語によっては、異なる文脈で異なる意味を有することがあります。「saw」は、名詞(例えば、切断に使用される鋸)または現在の緊張動詞(何かを切断する鋸を使用する)であってもかまいません。
言語を理解するための論理的な第一歩は、文中の各単語についてこれらの役割を把握することです。このプロセスは品詞( POS : _Part-of-Speech_ )タグ付けと呼ばれます。役割はPOSタグと呼ばれます。与えられた単語は文脈によって複数の可能性のあるタグを持つかもしれませんが、文章の解釈があれば、一般に各単語は1つのタグしか持ちません。
POSタグ付けの興味深い課題の1つは、特定の言語に対してPOSタグの語彙を定義する問題がかなり関わっていることです。名詞と動詞の概念はかなり共通していますが、伝統的にすべての言語にわたる標準的な役割セットに同意することは困難でした。 Universal Dependencies プロジェクトは、この問題を解決することを目指しています。
SyntaxNet POS タガーの訓練
一般的に、正しい POS タグを決定するには、文全体とそれが発声された文脈を理解する必要があります。実際には、興味のある単語の周りに小さな単語のウィンドウを考慮するだけで、とてもうまくやることができます。たとえば、「the」という単語に続く単語は、動詞ではなく形容詞または名詞になる傾向があります。
POS タグを予測するには、簡単な設定を使用します。文章を左から右に処理します。与えられた単語に対して、その単語の特徴とその周囲の窓を抽出し、これらを POS タグ上の確率分布を予測するフィードフォワードニューラルネットワーク分類器への入力として使用します。意思決定は左から右の順番で行われるため、前の決定を後続の決定の特徴としても使用します(たとえば、「前の予測タグは名詞でした」など)。
このパッケージのすべてのモデルは柔軟なマークアップ言語を使用して機能を定義します。たとえば、 POS タガーの機能は TaskSpec の brain_pos_features パラメータにあり、次のようになります(モジュロスペーシング)。
stack(3).word stack(2).word stack(1).word stack.word input.word input(1).word input(2).word input(3).word;
input.digit input.hyphen;
stack.suffix(length=2) input.suffix(length=2) input(1).suffix(length=2);
stack.prefix(length=2) input.prefix(length=2) input(1).prefix(length=2)
ここで stack とは、「タグが付いた単語」を意味します。 したがって、この機能仕様では、単語、接尾辞、接頭辞の3種類の機能が使用されます。 機能は、埋め込み行列を共有し、連結され、一連の隠れ層に供給されるブロックにグループ化されます。 この構造は、 ChenとManning(2014) が提案したモデルに基づいています。
このレイアウトを以下の図に示します。システムの状態(スタックとバッファ(POSと依存性解析タスクの両方について下に表示されます))を使用して、グループ内のネットワークに供給される希薄なフィーチャを抽出します。 スケマティック内のプレゼンテーションを簡略化するために、フィーチャの小さなサブセットのみを示します。

上記の構成では、各ブロックが独自の埋め込み行列を取得し、上記の構成のブロックはセミコロンで区切られています。 各ブロックの次元は、 brain_pos_embedding_dims パラメータで制御されます。
重要な注意 :多くの単純な NLP モデルと異なり、これは単語モデルの袋では _ありません_ 。 特定の機能は埋め込み行列を共有しますが、上記の機能は連結されるため、 input.word の解釈は input(1).word とはかなり異なることに注意してください。 これは、機能を追加すると、モデルの concat (連結)層の次元と、第1隠れ層のパラメータ数が増加することも意味します。
モデルを訓練するには、最初に syntaxnet/context.pbtxt を編集して、訓練コーパス、チューニングコーパス、および開発コーパスの入力が訓練データの場所を指すようにします。 次に、品詞タグを訓練することができます:
bazel-bin/syntaxnet/parser_trainer \
--task_context=syntaxnet/context.pbtxt \
--arg_prefix=brain_pos \ # POS設定から読み込み
--compute_lexicon \ # パイプラインの第1ステージで必要
--graph_builder=greedy \ # beam search なし
--training_corpus=training-corpus \ # 訓練/チューニングセットの名前
--tuning_corpus=tuning-corpus \
--output_path=models \ # 新規リソースをどこに格納するか
--batch_size=32 \ # ハイパーパラメータ
--decay_steps=3600 \
--hidden_layer_sizes=128 \
--learning_rate=0.08 \
--momentum=0.9 \
--seed=0 \
--params=128-0.08-3600-0.9-0 # パラメータの名前
これは、データを読み込み、レキシコン(辞書)を構築し、特定のハイパーパラメータでモデルの TensorFlow グラフを作成し、モデルを訓練する。 モデルはチューニングセットで評価されることが多く、このセットで最高精度のチェックポイントだけが保存されます。 チューニングセットとしてモデルをテストするコーパスを決して使用しないでください。テストセットの結果が膨らんでしまうためです。
最良の結果を得るには、少なくとも3つの異なるシードで --rearning_rate と --decay_steps にいくつかの異なる値を指定してこのコマンドを繰り返す必要があります。 --learning_rate の値は通常0.1に近く、通常は --decay_steps がコーパスの約1/10に相当するようにします。 --params フラグは、訓練を受けているモデルの人間が読める識別子で、完全な出力パスを構築するために使用されるため、偶然古いモデルを壊す心配はありません。
--arg_prefix フラグは、タスクコンテキストファイル context.pbtxt から読み込むパラメータを制御します。 この場合、 arg_prefix は brain_pos に設定されているため、このトレーニングで使用されているパラメータは brain_pos_transition_system 、brain_pos_embedding_dims 、 brain_pos_features 、および brain_pos_embedding_names です。 依存関係パーサーを訓練するには、後で arg_prefix が brain_parser に設定されます。
タガーの事前処理
訓練されたPOSタグ付けモデルが完成したので、このモデルの出力をパーサの機能として使用したいと考えています。 したがって、次のステップは、訓練されたモデルを訓練、チューニング、および開発(評価)セットで実行することです。 このために parser_eval.py スクリプトを使うことができます。
たとえば、上でトレーニングしたモデル 128-0.08-3600-0.9-0 は、次のコマンドを使用して、訓練、チューニング、および dev セットを介して実行できます:
PARAMS=128-0.08-3600-0.9-0
for SET in training tuning dev; do
bazel-bin/syntaxnet/parser_eval \
--task_context=models/brain_pos/greedy/$PARAMS/context \
--hidden_layer_sizes=128 \
--input=$SET-corpus \
--output=tagged-$SET-corpus \
--arg_prefix=brain_pos \
--graph_builder=greedy \
--model_path=models/brain_pos/greedy/$PARAMS/model
done
重要な注意 :このコマンドは、 tagged-training-corpus 、 tagged-dev-corpus 、および tagged-tuning-corpus に対応するエントリを context.pbtxt に作成した場合のみ機能します。 これらのデフォルト設定から、上記では、training、tuning、およびdevのタグバージョンをディレクトリ model/brain_pos/greedy/$ PARAMS/ に書き出します。 このエントリは、入力エントリに file_pattern が設定されていないため選択されます。代わりに、 creator:brain_pos/greedy があります。つまり、 --arg_prefix=brain_pos --graph_builder=greedy を使用して parser_trainer.py が呼び出されたときに、 --model_path フラグを使用して場所を特定します。
便宜上、 parser_eval.py は出力されたタグ付きデータセットが書き込まれた後もPOSタグ付けの精度を記録します。
h3. 依存関係の解析:遷移ベースの解析
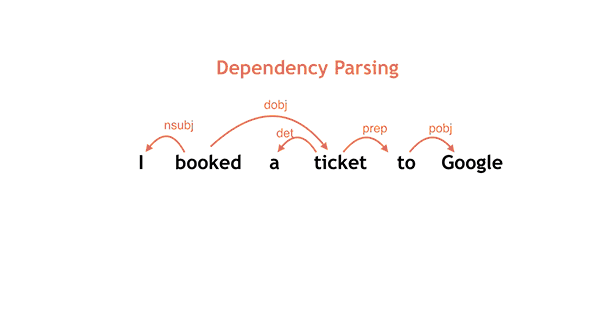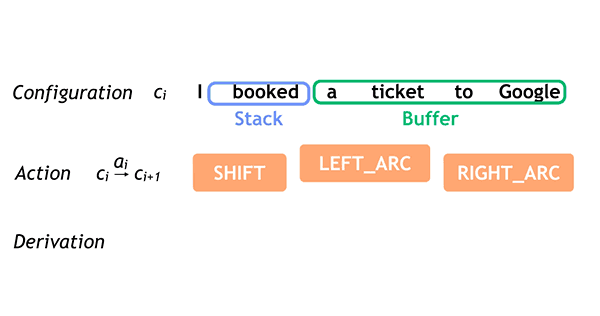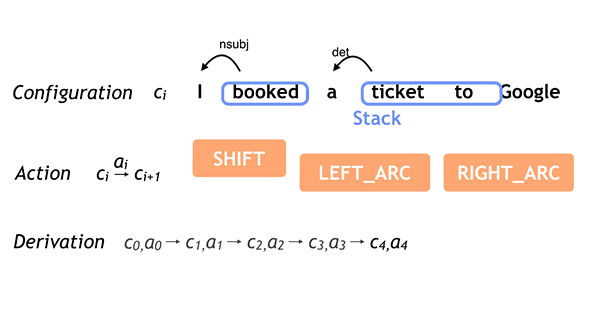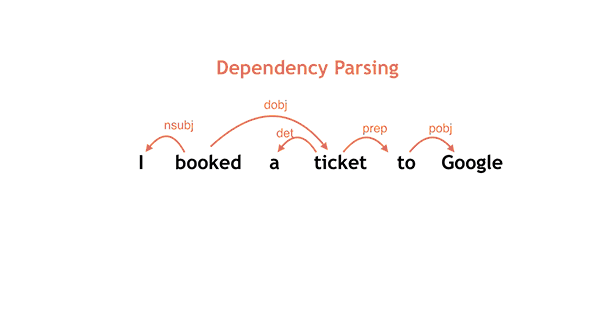
ここまでで、単語の文法的役割の予測を取得したので、次に文中の単語がどのように関係しているかを理解したくなるでしょう。 このパーサは、 _頭修飾子(head_modifier)_ の構成に基づいてビルドされています。各単語について、文法上の役割に応じて修正する _構文頭(synactic head)_ を選択します。
上記の文の例は次のとおりです:

文中の各単語の下には、細かい品詞( _PRP(人を表す代名詞)_ 、 _VBD(動詞過去形)_ 、 _DT(冠詞)_ 、 _NN(名詞単数形)_ など)と粗い品詞( _PRON(代名詞)_ 、 _VERB(動詞)_ 、 _DET(限定詞)_ 、 _NOUN(名詞)_ など)があります。粗粒のPOSタグは、基本的な文法カテゴリをエンコードしますが、細粒度のPOSタグはさらに区別します。たとえば、NNは単名詞(NNSとは異なり、複数名詞です)、VBDは過去 - 動詞。さらなる議論については、 Petrov et al.(2012) を参照してください。
極めて重要な事ですが、先の図では文中の異なる単語間の文法的関係を示す矢印付き弧が示されています。例えば、 I は saw の主語ですが、これらの単語の間に nsubj とラベル付けされた有向弧によって示されています。 man は saw の直接の目的語(dobj)です。前置詞 with は、前置句による修飾をあらわす関係 prep で man を修飾します、等です。加えて、動詞 saw は、文全体の root として識別されています。
2つの単語の間に有向弧があるときはいつも、弧の先頭の単語を head(頭) 、弧の最後の単語を modifier(修飾子) と呼んでいます。例では、 頭がsaw で修飾子が I 、もうひとつの弧は頭が saw で修飾子が man であることが示されています。
依存構造でコード化された文法的関係は、問題の文の根底にある意味に直接関係しています。 それは、 私が誰に見えたのか? 、 誰が眼鏡を持っているのか? など、様々な質問への回答を簡単に取り戻すことができます。
SyntaxNet は、パースを段階的に構築する 遷移ベース の依存関係パーサ Nivre (2007) です。タガーと同様に、左から右の単語を処理します。すべての単語は、 _バッファ_ と呼ばれる未処理の入力として開始します。単語が出現すると、それらは スタック に置かれます。各ステップで、パーサは次の3つのうちのいずれかの実行が可能です:
- SHIFT : スタックの最上部に別の単語をプッシュします。つまり、バッファからスタックに1つのトークンを移動します。
- LEFT_ARC : スタックから上位2つの単語をポップします。 最初のものに2番目のものを付けて、左を指す弧を作成します。 最初の単語をスタックに戻します。
- RIGHT_ARC :スタックから上位2つの単語をポップします。 2番目を最初に付け、右に円弧の点を作成します。 2番目の単語をスタックに戻します。
各ステップでは、スタックとバッファの組み合わせをパーサーの構成と呼びます。 左右のアクションについては、依存関係ラベルもその弧に割り当てます。 このプロセスは、短い文章の場合、次のアニメーションで視覚化されます。
このパーサは、言語学者によってラベル付けされた「金」ツリーを生成するために、 派生(derivation) と呼ばれる一連のアクションに従っていることに注意してください。 この一連の決定を使用して、構成を取り、次に実行するアクションを予測する分類子を学習できます。
パーサ訓練ステップ1:ローカルプレトレーニング
我々の 論文 で説明したように、モデルのトレーニングの第一歩は、現地の意思決定を使って事前にトレーニングすることです。 このフェーズでは、パーサを導くために金の依存関係を使用し、これらの金の依存関係に基づいて正しいアクションを予測するためにsoftmaxレイヤを訓練します。 この設定では、パーサの決定はすべて独立しているので、これは非常に効率的に実行できます。
タグ付きデータセットが利用可能になると、次のコマンドを使用して、ローカルで正規化された依存関係解析モデルを習得できます:
bazel-bin/syntaxnet/parser_trainer \
--arg_prefix=brain_parser \
--batch_size=32 \
--projectivize_training_set \
--decay_steps=4400 \
--graph_builder=greedy \
--hidden_layer_sizes=200,200 \
--learning_rate=0.08 \
--momentum=0.85 \
--output_path=models \
--task_context=models/brain_pos/greedy/$PARAMS/context \
--seed=4 \
--training_corpus=tagged-training-corpus \
--tuning_corpus=tagged-tuning-corpus \
--params=200x200-0.08-4400-0.85-4
トレーナは、以前に選んだPOSタガーに対応するコンテキストを指すことに注意してください。 これにより、パーサは、前の手順で作成されたレキシコン(辞書)とタグ付きデータセットを再利用できます。 データの処理は、上記のタグ付け方法と同様に行うことができます。 たとえば、この場合、パラメータ 200x200-0.08-4400-0.85-4 を選択した場合、トレーニング、チューニング、およびdevセットは、次のコマンドで解析できます:
PARAMS=200x200-0.08-4400-0.85-4
for SET in training tuning dev; do
bazel-bin/syntaxnet/parser_eval \
--task_context=models/brain_parser/greedy/$PARAMS/context \
--hidden_layer_sizes=200,200 \
--input=tagged-$SET-corpus \
--output=parsed-$SET-corpus \
--arg_prefix=brain_parser \
--graph_builder=greedy \
--model_path=models/brain_parser/greedy/$PARAMS/model
done
パーサ訓練ステップ2:グローバルトレーニング
この論文で説明しているように、私たちが訓練したばかりのローカル正規化モデルにはいくつかの問題があります。 最も重要なのはラベルバイアス(label-bias)問題です。このモデルでは、適切な解析がどのように見えるのか、金の決定の履歴を考慮して、どのようなアクションを取るのかだけを学習します。 これは、各決定にsoftmaxを使用してスコアを _ローカルで_ 正規化するためです。
このモデルでは、 _グローバルに_ 正規化されたモデルを使用してより良い結果を達成する方法を示しています。このモデルでは、softmax スコアはログスペースで合計され、最終的な決定が得られるまでスコアは正規化されません。 パーサが停止すると、各仮説のスコアは、可能な解析の小さなセットに対して正規化されます(このモデルの場合、ビームサイズは8です)。 訓練をすると、金の導出がビームから落ちるときにパーサを解析することが強制されます(早期更新と呼ばれる戦略)。
我々は、複数の仮説を維持することが重要である ガーデンパス文 に対して、この訓練がどのように機能するかを簡略化して示している。 構文解析の際に最初に間違いがあった場合、完全に間違った解析が行われます。 トレーニングの後、モデルは第2の(正しい)解析を好むことを学びます。

Parsey McParsefaceはこの文を正しく解析します。 Parsey McParsefaceは、ガーデンパス文の終わりに達すると、適切な解析が複数の仮説の中で最初に4番目にランク付けされても、ビームによって回復することができます。 より大きなビームを使用すると、より正確なモデルが得られますが、速度は遅くなります(モデルのビーム32を使用します)。
事前にトレーニングされたローカル正規化モデルを取得したら、次のコマンドを使用してグローバルに正規化された解析モデルを習得できます:
bazel-bin/syntaxnet/parser_trainer \
--arg_prefix=brain_parser \
--batch_size=8 \
--decay_steps=100 \
--graph_builder=structured \
--hidden_layer_sizes=200,200 \
--learning_rate=0.02 \
--momentum=0.9 \
--output_path=models \
--task_context=models/brain_parser/greedy/$PARAMS/context \
--seed=0 \
--training_corpus=projectivized-training-corpus \
--tuning_corpus=tagged-tuning-corpus \
--params=200x200-0.02-100-0.9-0 \
--pretrained_params=models/brain_parser/greedy/$PARAMS/model \
--pretrained_params_names=\
embedding_matrix_0,embedding_matrix_1,embedding_matrix_2,\
bias_0,weights_0,bias_1,weights_1
構造化されたビルダーでビームモデルをトレーニングするには、上記の貪欲なトレーニングよりも、おそらく3〜4倍長い時間がかかります。 トレーニングの複数の再開が最も信頼性の高い結果をもたらすことに再度注意してください。 評価は、 parser_eval.py で再度行うことができます。 この場合、パラメータ 200x200-0.02-100-0.9-0 を使用して、次のコマンドでトレーニング、チューニング、およびdevセットを評価します。
PARAMS=200x200-0.02-100-0.9-0
for SET in training tuning dev; do
bazel-bin/syntaxnet/parser_eval \
--task_context=models/brain_parser/structured/$PARAMS/context \
--hidden_layer_sizes=200,200 \
--input=tagged-$SET-corpus \
--output=beam-parsed-$SET-corpus \
--arg_prefix=brain_parser \
--graph_builder=structured \
--model_path=models/brain_parser/structured/$PARAMS/model
done
やめ! あなたは今Parsey McParsefaceのあなた自身のいとこを持っています。外に出て、ワイルドなテキストを解析する準備ができています。
コンタクト
質問や問題報告は、タグsyntaxnetをつけてStack Overflowに投稿するか、tensorflow/models issues trackerに問題をオープンしてください。 @calberti や @andorardo にSyntaxNet の問題を割り当ててください。
クレジット
このパッケージのに含まれているコードのオリジナル著者リスト(アルファベット順):
- Alessandro Presta
- Aliaksei Severyn
- Andy Golding
- Bernd Bohnet
- Chris Alberti
- Daniel Andor
- David Weiss
- Emily Pitler
- Greg Coppola
- Ji Ma
- Keith Hall
- Kuzman Ganchev
- Michael Collins
- Michael Ringgaard
- Ryan McDonald
- Slav Petrov
- Stefan Istrate
- Terry Koo
- Tim Credo
以上
-----------
yahoo 翻訳を使っていたときは、正直辞書をひかないで済む程度の翻訳レベルだったのに、
Google翻訳はほぼ全文をそのまま使用できる..
saw を「見る」と「ノコギリ」に区別するところもすんなり翻訳できた..
ただ..頭と修飾子のくだりは、さすがに混乱してまともな文章でかえさなかったが、
そのあたりだけこちらで直せばほぼ完璧と行っていいくらい..
おそらく、Google翻訳こそこのSyntaxNetのReference Implementsなのだろう..
ためしてみようかな..
yahoo 翻訳を使っていたときは、正直辞書をひかないで済む程度の翻訳レベルだったのに、
Google翻訳はほぼ全文をそのまま使用できる..
saw を「見る」と「ノコギリ」に区別するところもすんなり翻訳できた..
ただ..頭と修飾子のくだりは、さすがに混乱してまともな文章でかえさなかったが、
そのあたりだけこちらで直せばほぼ完璧と行っていいくらい..
おそらく、Google翻訳こそこのSyntaxNetのReference Implementsなのだろう..
ためしてみようかな..