前に書いた記事「TensorFlow 1.4.0 rc0 がリリースされていた」
にでてきたとおり、
TensorFlow 1.4.0 リリースの核は
Estimator
であるのは明白だ。
いろんな機械学習モデルの実装が
Estimator としてこれから提供されるだけでなく
学習済み機械学習モデルは
缶詰めされた Esatimator (Canned Estimator)としても提供される。
すぐに鎮火すると思っっていた人工知能ブームだったが、
自動運転やチャットボットとかの台頭と
顧客がいまだ何に使えるかわかっていない状態が続き
幻滅期に一気に移行しなかったようで、
そうこうしているうちに
コグニティブ API 流用レベルのいっちょかみSIer
にも
私のように勉強する時間ができ
TensorFlowやChainer、Theano、Kerasなどの
ライブラリを使った機械学習いっちょかみSIer
へレベルが徐々にあがってきた。
この「機械学習いっちょかみSIer」が最近
「いまだ何に使えるかわかっていない顧客」に
学習済み機械学習モデルを流用して類似事例に転用して
高値で売りつけるようになってきた..気がする。
機械学習を少し勉強した人は単なる「転移学習(Tranfer Learning)」の流用に過ぎないが
VGG16やのInseptionV3やらの性能の良い学習済み画像分類器なんかが
ライブラリに入っているものだから..
..と、話がそれていきそうなのでやめにするが...
ようはこれから至近何ヶ月かは
Canned Estimator の時代
が来ていることを個人的に実感している。
転移学習は基本、
少ない学習データで学習済みモデルを追加学習させる方法
なのだけど、
これをやるには
学習済みモデルのお尻の層数層+新規の層数層を加えて
少ない学習データをバッチ実行させて追加学習させ無くてはならない。
Keras の VGG16 とかの既存学習モデルは
はなっからそう使われるだろうなと想定されていて
簡単に転移学習できるようになっているが
TensorFlowのEstimatorは
Estimator に合う入力データ、バッチデータにしてやらないといけない。
でもTensorFlowというライブラリは
バリバリのモデル自体の開発者向けという面をもっているので
入力データを input_fn という一定のルールで書かれた関数にしてやらないと
食わせることができない、いっちょかみできないのだ。
で、いろいろ調べているのだけど 1.4.0 が出たばっかりなので
本家サイト以外にさっぱり情報がない..
で、本家サイトを読んでいたらこのリンクを見つけた。
と、いうことで早速勝手に翻訳してみた。
ちょうどスライドのノート部分にDerek Murray氏の喋った内容も記載されているので
一緒に翻訳してみた。
以下その翻訳文だが、当然間違っていても一切責任はとりません。
参照する際は、at your own riskでお願いします。
-------


私はなぜ入力パイプラインについて話しているのしょう?
それは、入力データは機械学習の生命線だからです。
私たちはモデルを高精度に訓練するために巨大なデータセットに効率的にアクセスすることに頼りっきりになっているのです。

しかし、現在のアクセラレータ(GPU)は非常に枯渇しています。 NVIDIA の Volta や Cloud TPU のようなアーキテクチャは、数年前よりもはるかに高速であり、入力パイプラインから非常に高いスループットを要求して飽和状態を維持します。

率直に言うと、GPU枯渇はパフォーマンスの問題だけではありません...あなたのデータをTensorFlowに簡単に取り込む方法が必要です。
以前は、基本的に2つのオプションがありました...

ひとつは、feed_dict メカニズムです。
この方法では、すべての入力処理をTensorFlow 計算グラフ外の Pythonプログラム上に置いています。
これを行うことの良い点は、Pythonのもつ柔軟性を享受でき、任意のデータ形式での作業が容易になることです。
しかし、この方法ではパフォーマンスは悪くなることがあります。利用者はしばしば単一のスレッドで入力データを処理することとなり、それがクリティカルパスとなっています。その間アクセラレータは全くの役立たずとなるのです。

..また、2つめの選択肢として、あなたのプロセスを TensorFlow の C++ オペレーションに移して、それらを TensorFlow の "生産者/消費者" キューを使うために文字列化するという方法もあります。
このスライド上のこのようなAPIは、ちょっとした待ち行列を構築し、パイプラインを与え、並列性を得ることで、データを placeholder へコピーする時間の合計を削減させています。
TensorFlowプログラムで ”キューランナーの開始(start queue runnners)" を聞いたことがありますか?これは、待ち行列の間で要素を移動する小さなグラフを実行するためにPythonスレッドを分岐させる神秘的なライブラリコールのことです。(start queu runnerを)呼び出すことを忘れても、複雑な並列 Python プログラムを実行してキューをいっぱいにしておく必要があります。グローバルインタープリタロックは、1秒あたりに処理できるレコード数を厳しく制限します。
コンセプト上の欠点もあります。--いい意味で--APIがこれらのスレッドの詳細を隠蔽しようとするため、キューベースのパイプラインはすべての入力データに対して単一のグローバルな1回限りのパイプラインになり、実行時に入力ソースを変更することはほとんど不可能になります。
このため、これらよりも高速で、キューよりもはるかに使いやすい代わりになるAPIを設計したいと考えたのです。

では、なぜ我々が、関数入力パイプラインのための新しいTensorFlow APIである tf.data のために数ヶ月を費やしたのかについて話したいと思います。
ここでは、みなさんに APIのツアーを提供して、あなたが何をすることができるかを示していきたいと思います。
私たちがtf.data を設計していたときは、機能プログラミングの分野からも重要な洞察が得ていました。
入力パイプラインは、関数型言語における"のろまなリスト(遅延リスト:lazy list)"のようなものなのです。
何故我々がそう設計したと思いますか?

データ要素はほとんど同質であるため、(Pythonの)listのようなものと同じです。フィーチャは異なるshapeを持つこともありますが、一般的には同じタイプのフィーチャを持ちます。

データセット全体が大きすぎてすべてを一度に実現できない場合や、データを自分で生成している場合は無限になる可能性があります。
そこれ、それらをlazy(=のろま)にすることを考えました。
一旦のろまなリストのようなそれらについて考え始めると、どうして map() や filter() のような高次関数を作成するのかがわかるとおもいます。

これは決して新しい考えではなく、実際にはC# の LINQ 、Scala のコレクション、 Java8 のストリームなどの主流言語の標準ライブラリの一部にもなっています。 そして、まったく正直なところ、斬新さの欠如はここでは良いことです。それが定石としてうまくいくことはわかっていますし、Stream Fusion、Shortcut Deforestation、そしてもしかすると、パフォーマンスを向上させるためのSQLクエリの最適化などで--あなたも書いたことのあるようなプログラム最適化に関する膨大な文献があります。
したがって、入力パイプラインを機能的なプログラムとして記述することができれば、良い形になります...

...これが、関数入力パイプライン用の新しいTensorFlow APIであるtf.dataを作成した理由です。

tf.data には、TensorFlowプログラムへの2つの新しいインターフェイスが導入されています。
1つは、要素のコレクションを表す Dataset インターフェイスです。関数型のアナロジーが好きだった場合-- Dataset はテンソルのタプルののろまなリストと考えることができます。

それらをどのようにして作成するかについての幾つかのデータセットの例を紹介します。
最初のデータセットの例は "ソース" で、1つ以上のテンソルオブジェクトから作成しています。

たとえば、最も簡単なソースは Dataset.from_tensors() で、これはテンソルのタプルから単一要素のデータセットを作成しています。

これらのテンソルを複数の要素に分割したい場合は、 "from_tensor_slices"を使用します。

もしデータをディスクから取得するのであれば、TextLineDatasetなどのファイルリストを読み取るファイル形式パーサを使用して、これらのファイル内の各行に対して1つの文字列要素を含むデータセットを生成することができます。

第2の選択肢としては、機能変換を使用して1つのデータセットを別のデータセットに変換することです。 一覧でおみせするにはあまりにも多くの変換があるのですが、より一般的なもののいくつかは以下を含みます...

...map(), ここではデータセットの各要素へ関数を適用します...

... repeat() を使用して、入力データセットを複数回ループすることができます...
...そしてバッチ、ここでは元のデータセットから複数の連続した要素をまとめてバッチを作成します。

そして、APIには数多くの基本的な変換があります(主に標準的な高次関数のリストに基づいており、それらを組み合わせてより複雑なものにすることができるように設計されています)。

この良いサンプルとしては、TensorFlow 1.4に追加した py_func opといくつかの標準データセットから作成した新しい Dataset.from_generator() のソースです。
このソースを使用すると、入力処理ロジックをPythonジェネレータとして記述することができます。これをデータセットに変換して、他の変換と一緒に作成することができます。 これはユーザの生産性を変えるものであり、数週間しか利用できないにもかかわらず、 feed に慣れている方がより良い成果を望む場合はより簡単になると思います。

さあ、それをまとめてみましょう。 ファイル名のリストから始めて、TFRecordDatasetを使ってレコードをバイナリ blob として取得し、構文解析関数をマップしてテンソルに変換し、ランダムシャッフルし、100回のトレーニングを繰り返し、最後に128個の連続要素のバッチを連結し単一の要素に変換します。
多くの人々の最初のデータセットパイプラインはこのように見えます。シャッフルリピートバッチは、ミニバッチSGDを実行するときの共通のモチーフです。
データセットのパイプラインを読んで、 feed やキューベースのプログラムを見ているよりも、何が起こっているのかを簡単に伝えることができていたらうれしいのですが。

パイプラインをデータセットとして定義してきました。
あなたはどの方法でモデルをトレーニングするためにテンソルを取得しましたか?
2つめの補足は Iterator インターフェイスです。Iterator は他のプログラミング言語のイテレータとよく似ています。Iterator はデータセット内の現在の位置を維持し、テンソルのタプルとして次の要素にアクセスする方法を提供します。

iteratorメソッドを呼び出すことによってデータセットからIteratorを作ることができます。ここにはいくつかのオプションがあります。

単純なケースでは、1回のみのイテレータがうまく機能します。自動的に初期化され、データを1回通過させることができます。これは、基本的にキューから取得できる機能を提供します。

より高度なオプションは、初期化可能なイテレータで、複数のデータソース間の切り替えなど、より洗練された使い方を提供しています...

..主な違いは、初期化可能なイテレータは、初期化のために実行できるオペレーションを与えることができます。
・複数回実行可能
で
・異なるファイルリストや異なるエポック数などのようなパラメータを実行時にfeed可能です。

イテレータを設定したら、 get_next() メソッドを使用してイテレータから次の要素にアクセスできます。 これは古典的な TensorFlow で、遅延実行があるため、session.run に渡して次の要素を生成する必要があります。

実際にどうやって使うのでしょうか?
ここで、画像とラベルのバッチのデータセットがあるとします。
イテレータを作成し、get_nextの結果をあなたのモデルと最適化機能を使って訓練を行い、その訓練をループで実行します。
OutOfRangeErrorは、ファイルの終わりに対する私たちの魅力的な名前です。
この定型文をすべてあなた自身で書く必要はないことに注意してください...

たとえば、Estimator APIを使用している場合は、最初の数行を入力関数にラップするだけで、Estimatorがループ処理を行います。

キューではできないこともあなたに味わっていただきたいと思います。
(1エポックと呼んでいる単位の)データを正確に一通り実行し、次を開始する前に幾つかの エポック終了時の計算(end-of-epoch computation) を実行するとしましょう。
古いキューベースのAPIでは、基本的に単一のグローバルなone-shot(1回だけの) iterator があるため、これをやりたい場合はsessionを解体して再起動する必要があります。これは不器用で処理も遅くなります。
このスライドでは、初期化可能なイテレータがその問題をどのように解決するかを示しています。このように、エポックを越えて外側のループを持つことができます。そのループの始めにイテレータを初期化し、範囲外になるまで訓練し、最後にエポックの計算を行い、パイプラインを再起動します。
エポック終了時の計算では、検証のために別のデータセットを反復処理する必要があるかもしれません。あるいは、イニシャライザをパラメータ化して、各エポックで異なる処理を行うこともできます。

tf.data APIをまとめましょう。
ここでは、学ぶべき2つの新しいクラスがありました。
tf.data.Dataset では、データソースと機能変換の構成としての入力パイプラインを表しました。
また、tf.data.Iteratorを使用すると、データセットから要素にシーケンシャル(順番)にアクセスすることができました。
うまくいけば、既存のAPIよりシンプルであると確信しています。
tf.data の柔軟性は次の2つの点からもたらされます:
・複雑なパイプラインを構築するために一緒に構成された豊富な変換セット
と
・同じプログラム内に複数のデータセットとイテレータを作成できるため、振る舞いをパラメータ化してさまざまなソース間を切り替えることが可能
なことです。

パフォーマンスについても少し語りたいとおもいます。
ここでの努力に対する全ての目的は、使いやすく高速なものを作ることにあります。

あなたがこれまでずっと feed_dict ベースのプログラミングをしてきているのであれば、かなりのスピードアップを期待できるでしょう。
実装されている内容を詳しく説明する時間はありませんが、主な性能向上ポイントとしては、Pythonのオーバーヘッドを避けるために C++ で tf.data を実装しているところにあります。
tf.data パイプラインを同等のキューベースのパイプラインと比較すると、同様の構造のキューとスレッドが使用されますが、クリティカルパスには Python キューランナースレッドが存在しないため、tf.data パイプラインは グローバルインタープリタロックによって制限され、より高いスループットにエンハンスされます。

ただし、現在の実装は、デフォルトでは決定論的(確定的)、順次および同期的です。 すべてのステージのバッファとスレッドを作成し、要素を生成するために競合するキューベースのAPIとは異なり、並列性と非決定性のオプトインを行うという控えめなアプローチをとってきました。 その理由の1つは、トレーニングモデルのRAM要件が非常に大きくなる可能性があるということです。1つのバッチはマルチGPUイメージモデルでは数百MBから数ギガバイトになる可能性があり、コンピュータのスラッシングを開始するよりも遅く予測可能です。
幸いにも、我々はより高いパフォーマンスの選択を容易にしました...

このデータセットのサンプルを見て、パフォーマンス関連のコードを入れようとしている不審なスペースをつかって再編成してみしましょう!
私は努力順で行くつもりです...

まず、非同期パイプラインを有効にし、dataset.prefetch() でこれを行うことができます。これは本質的に恒等変換ですが、バックグラウンドスレッドとバインドされたバッファを作成して要素をプリフェッチします。
残りのパイプラインのコストが安い場合は、現在のバッチのトレーニングと次のバッチの事前処理を重複させることができます。

事前処理がより大変な場合は、並列化したくなるかもしれません。
これは、 num_parallel_calls を dataset.map() に追加するだけで簡単にできます。
今度は、TensorFlowスレッドプールを使用して一度に64レコードを解析します。

最後の方法は、GCSのような分散ファイルシステムを使ってデータを保存する場合に最も便利です。
ファイルベースのデータセットでは、一度に1つのファイルが読み込まれるため、ほとんどの時間を I/O のブロックに費やす可能性があります。
この小さなインターリーブとプリフェッチガジェットを使用すると、8つのファイルを同時に読み込み、バッファを保持してレイテンシの変動を隠すことができます。

さて、ここまで新しい tf.data API を紹介してきました。
セッションの終盤は、今後何が起こっていくのかを知りたいだけだとおもいます。
私はすでに、TensorFlow 1.4 において API が tf.dataに移動していると述べました。
これのバージョンから、後方互換性の保証をしていきます。みなさんのプロダクトではそれに頼ることをお勧めします。

我々の次の大きな目標は、GPUメモリへの自動ステージングを可能にすることです。 これはパフォーマンスにとって重要です。プログラムの1行の変更でこれを有効にする必要があります。

そして長期的には、自動パフォーマンス最適化のチャンスに興味があります。 私は既に静的最適化に関する豊富な文献があると述べましたが、新しいAPIは、実行時にバッファサイズ、スレッド数、プレースメントを設定する興味深い可能性を与えてくれますし、これらを最適化するLearning2Learnや強化学習のテクニックのような事さえ使うでしょう。

このセッションでは、TensorFlow内へのデータ取得は苦痛を伴うものではないことを示しました。
tf.data はシンプルですが、高速で、柔軟性があり、以前はできなかったあらゆることを行うことができます。
あなたがそれを使って構築することを聞くのが待ちきれません。
ああ。 また、私たちが公開したばかりの基礎を紹介するブログポストもあります...
聞いてくれてありがとう、質問をいただけると嬉しいのですが..

-------
..多分ノート部分は、
Youtubeの自動テロップ機能の出ててきた英語をそのままではなく
直しているのだとおもうのだけど、
ところどころ..ああ、ここ、ドヤ顔してるな..きっと..というのが
よめる英語だった..
実装のスードコードが載っていたので
非常によくわかった。
キューっていうモノがあるのは
本家サイトを翻訳していたときから知ってはいたんだけど、
(もちろん非同期の基本モデルの登場人物だってことも)
これまでは「まずは動作させること」に命を燃やしていたので
feed_dict 経由一本槍だった..
..たしかに feed_dict で投入する段階って、
TensorFlow の C++ の実装との境界レベルだともうので
そこまでずーっとシングルスレッド一本で書いてたら
遅くなるよなあ..
..入力層にデータを入れるところからが
機械学習と思っているほかのライブラリと違って、
TensorFlowは
データ入力するところ(事前処理)も機械学習ですって
いっているわけね。
バッチ毎回の豆乳までにその分のデータを用意すりゃいいでしょ
っていうことで遅延リストを使うあたり
DBアクセスのHibernateっぽい..
やっぱコンピュータは I/O がボトルネックになるのは
基本中の基本ということか..
にしても.. バッチ1回毎に学習データに変化を持たせる..
..域まで機械学習こなしてないなあ..
..最先端の機械学習屋はそんなこともやってるんだ..
p.s.
そうか..
これからしばらくは、
Qiitaとかに出してるTensorFlowサンプルコードや
人の書いたコードとかの
session を withしてるなかで
feed_dictをつかっていたら
「まだまだ、わかってないね、チミ(シー、シー)」
とか言えば、
TensorFlowなんちゃって玄人
にすぐなれるってことか..
..もちろん、
この記事を読んでいる人は
みないい人たちだから
そんなことしませんよね...
にでてきたとおり、
TensorFlow 1.4.0 リリースの核は
Estimator
であるのは明白だ。
いろんな機械学習モデルの実装が
Estimator としてこれから提供されるだけでなく
学習済み機械学習モデルは
缶詰めされた Esatimator (Canned Estimator)としても提供される。
すぐに鎮火すると思っっていた人工知能ブームだったが、
自動運転やチャットボットとかの台頭と
顧客がいまだ何に使えるかわかっていない状態が続き
幻滅期に一気に移行しなかったようで、
そうこうしているうちに
コグニティブ API 流用レベルのいっちょかみSIer
にも
私のように勉強する時間ができ
TensorFlowやChainer、Theano、Kerasなどの
ライブラリを使った機械学習いっちょかみSIer
へレベルが徐々にあがってきた。
この「機械学習いっちょかみSIer」が最近
「いまだ何に使えるかわかっていない顧客」に
学習済み機械学習モデルを流用して類似事例に転用して
高値で売りつけるようになってきた..気がする。
機械学習を少し勉強した人は単なる「転移学習(Tranfer Learning)」の流用に過ぎないが
VGG16やのInseptionV3やらの性能の良い学習済み画像分類器なんかが
ライブラリに入っているものだから..
..と、話がそれていきそうなのでやめにするが...
ようはこれから至近何ヶ月かは
Canned Estimator の時代
が来ていることを個人的に実感している。
転移学習は基本、
少ない学習データで学習済みモデルを追加学習させる方法
なのだけど、
これをやるには
学習済みモデルのお尻の層数層+新規の層数層を加えて
少ない学習データをバッチ実行させて追加学習させ無くてはならない。
Keras の VGG16 とかの既存学習モデルは
はなっからそう使われるだろうなと想定されていて
簡単に転移学習できるようになっているが
TensorFlowのEstimatorは
Estimator に合う入力データ、バッチデータにしてやらないといけない。
でもTensorFlowというライブラリは
バリバリのモデル自体の開発者向けという面をもっているので
入力データを input_fn という一定のルールで書かれた関数にしてやらないと
食わせることができない、いっちょかみできないのだ。
で、いろいろ調べているのだけど 1.4.0 が出たばっかりなので
本家サイト以外にさっぱり情報がない..
で、本家サイトを読んでいたらこのリンクを見つけた。
Introducing tf.data
Derek Murray
https://docs.google.com/presentation/d/16kHNtQslt-yuJ3w8GIx-eEH6t_AvFeQOchqGRFpAD7U/edit?usp=sharing
と、いうことで早速勝手に翻訳してみた。
ちょうどスライドのノート部分にDerek Murray氏の喋った内容も記載されているので
一緒に翻訳してみた。
以下その翻訳文だが、当然間違っていても一切責任はとりません。
参照する際は、at your own riskでお願いします。
-------

皆さん、私はDerek Murrayです。今日、私は入力パイプラインについてお話します。
このセッションでは、入力データ用の効率的で複雑なパイプラインを簡単に定義できる入力パイプライン用の新しいライブラリについて説明します。
ライブラリでは tf.data と呼ばれ、TensorFlow 1.2がリリースされた 5月に初めて登場しました...
...そして先日の1.4 リリースにて、TensorFlowをコアに無事移行になったことがアナウンスされました。
このセッションでは、入力データ用の効率的で複雑なパイプラインを簡単に定義できる入力パイプライン用の新しいライブラリについて説明します。
ライブラリでは tf.data と呼ばれ、TensorFlow 1.2がリリースされた 5月に初めて登場しました...
...そして先日の1.4 リリースにて、TensorFlowをコアに無事移行になったことがアナウンスされました。

私はなぜ入力パイプラインについて話しているのしょう?
それは、入力データは機械学習の生命線だからです。
私たちはモデルを高精度に訓練するために巨大なデータセットに効率的にアクセスすることに頼りっきりになっているのです。

しかし、現在のアクセラレータ(GPU)は非常に枯渇しています。 NVIDIA の Volta や Cloud TPU のようなアーキテクチャは、数年前よりもはるかに高速であり、入力パイプラインから非常に高いスループットを要求して飽和状態を維持します。

率直に言うと、GPU枯渇はパフォーマンスの問題だけではありません...あなたのデータをTensorFlowに簡単に取り込む方法が必要です。
以前は、基本的に2つのオプションがありました...

ひとつは、feed_dict メカニズムです。
この方法では、すべての入力処理をTensorFlow 計算グラフ外の Pythonプログラム上に置いています。
これを行うことの良い点は、Pythonのもつ柔軟性を享受でき、任意のデータ形式での作業が容易になることです。
しかし、この方法ではパフォーマンスは悪くなることがあります。利用者はしばしば単一のスレッドで入力データを処理することとなり、それがクリティカルパスとなっています。その間アクセラレータは全くの役立たずとなるのです。

..また、2つめの選択肢として、あなたのプロセスを TensorFlow の C++ オペレーションに移して、それらを TensorFlow の "生産者/消費者" キューを使うために文字列化するという方法もあります。
このスライド上のこのようなAPIは、ちょっとした待ち行列を構築し、パイプラインを与え、並列性を得ることで、データを placeholder へコピーする時間の合計を削減させています。
TensorFlowプログラムで ”キューランナーの開始(start queue runnners)" を聞いたことがありますか?これは、待ち行列の間で要素を移動する小さなグラフを実行するためにPythonスレッドを分岐させる神秘的なライブラリコールのことです。(start queu runnerを)呼び出すことを忘れても、複雑な並列 Python プログラムを実行してキューをいっぱいにしておく必要があります。グローバルインタープリタロックは、1秒あたりに処理できるレコード数を厳しく制限します。
コンセプト上の欠点もあります。--いい意味で--APIがこれらのスレッドの詳細を隠蔽しようとするため、キューベースのパイプラインはすべての入力データに対して単一のグローバルな1回限りのパイプラインになり、実行時に入力ソースを変更することはほとんど不可能になります。
このため、これらよりも高速で、キューよりもはるかに使いやすい代わりになるAPIを設計したいと考えたのです。

では、なぜ我々が、関数入力パイプラインのための新しいTensorFlow APIである tf.data のために数ヶ月を費やしたのかについて話したいと思います。
ここでは、みなさんに APIのツアーを提供して、あなたが何をすることができるかを示していきたいと思います。
私たちがtf.data を設計していたときは、機能プログラミングの分野からも重要な洞察が得ていました。
入力パイプラインは、関数型言語における"のろまなリスト(遅延リスト:lazy list)"のようなものなのです。
何故我々がそう設計したと思いますか?

データ要素はほとんど同質であるため、(Pythonの)listのようなものと同じです。フィーチャは異なるshapeを持つこともありますが、一般的には同じタイプのフィーチャを持ちます。

データセット全体が大きすぎてすべてを一度に実現できない場合や、データを自分で生成している場合は無限になる可能性があります。
そこれ、それらをlazy(=のろま)にすることを考えました。
一旦のろまなリストのようなそれらについて考え始めると、どうして map() や filter() のような高次関数を作成するのかがわかるとおもいます。

これは決して新しい考えではなく、実際にはC# の LINQ 、Scala のコレクション、 Java8 のストリームなどの主流言語の標準ライブラリの一部にもなっています。 そして、まったく正直なところ、斬新さの欠如はここでは良いことです。それが定石としてうまくいくことはわかっていますし、Stream Fusion、Shortcut Deforestation、そしてもしかすると、パフォーマンスを向上させるためのSQLクエリの最適化などで--あなたも書いたことのあるようなプログラム最適化に関する膨大な文献があります。
したがって、入力パイプラインを機能的なプログラムとして記述することができれば、良い形になります...

...これが、関数入力パイプライン用の新しいTensorFlow APIであるtf.dataを作成した理由です。

tf.data には、TensorFlowプログラムへの2つの新しいインターフェイスが導入されています。
1つは、要素のコレクションを表す Dataset インターフェイスです。関数型のアナロジーが好きだった場合-- Dataset はテンソルのタプルののろまなリストと考えることができます。

それらをどのようにして作成するかについての幾つかのデータセットの例を紹介します。
最初のデータセットの例は "ソース" で、1つ以上のテンソルオブジェクトから作成しています。

たとえば、最も簡単なソースは Dataset.from_tensors() で、これはテンソルのタプルから単一要素のデータセットを作成しています。

これらのテンソルを複数の要素に分割したい場合は、 "from_tensor_slices"を使用します。

もしデータをディスクから取得するのであれば、TextLineDatasetなどのファイルリストを読み取るファイル形式パーサを使用して、これらのファイル内の各行に対して1つの文字列要素を含むデータセットを生成することができます。

第2の選択肢としては、機能変換を使用して1つのデータセットを別のデータセットに変換することです。 一覧でおみせするにはあまりにも多くの変換があるのですが、より一般的なもののいくつかは以下を含みます...

...map(), ここではデータセットの各要素へ関数を適用します...

... repeat() を使用して、入力データセットを複数回ループすることができます...
...そしてバッチ、ここでは元のデータセットから複数の連続した要素をまとめてバッチを作成します。

そして、APIには数多くの基本的な変換があります(主に標準的な高次関数のリストに基づいており、それらを組み合わせてより複雑なものにすることができるように設計されています)。

この良いサンプルとしては、TensorFlow 1.4に追加した py_func opといくつかの標準データセットから作成した新しい Dataset.from_generator() のソースです。
このソースを使用すると、入力処理ロジックをPythonジェネレータとして記述することができます。これをデータセットに変換して、他の変換と一緒に作成することができます。 これはユーザの生産性を変えるものであり、数週間しか利用できないにもかかわらず、 feed に慣れている方がより良い成果を望む場合はより簡単になると思います。

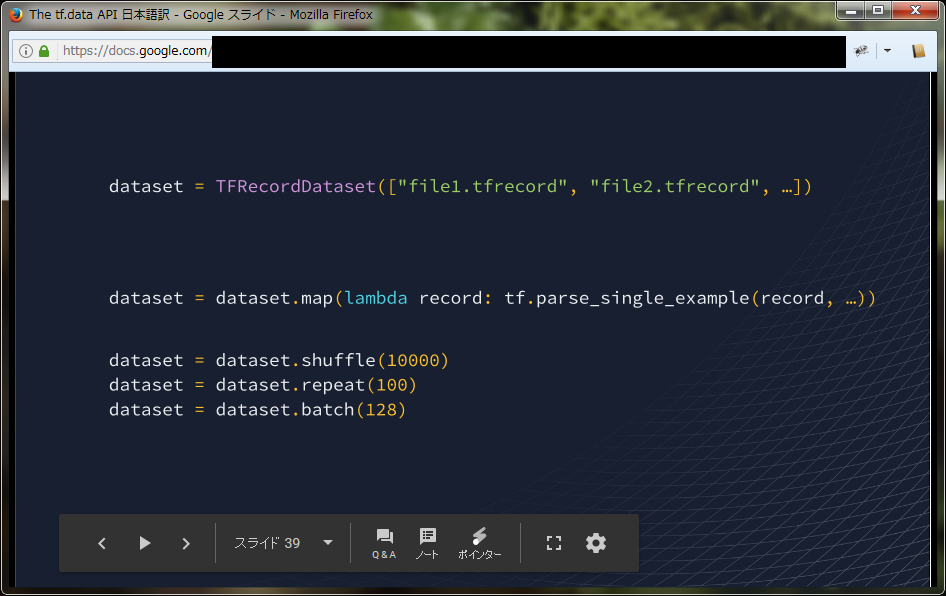
さあ、それをまとめてみましょう。 ファイル名のリストから始めて、TFRecordDatasetを使ってレコードをバイナリ blob として取得し、構文解析関数をマップしてテンソルに変換し、ランダムシャッフルし、100回のトレーニングを繰り返し、最後に128個の連続要素のバッチを連結し単一の要素に変換します。
多くの人々の最初のデータセットパイプラインはこのように見えます。シャッフルリピートバッチは、ミニバッチSGDを実行するときの共通のモチーフです。
データセットのパイプラインを読んで、 feed やキューベースのプログラムを見ているよりも、何が起こっているのかを簡単に伝えることができていたらうれしいのですが。

パイプラインをデータセットとして定義してきました。
あなたはどの方法でモデルをトレーニングするためにテンソルを取得しましたか?
2つめの補足は Iterator インターフェイスです。Iterator は他のプログラミング言語のイテレータとよく似ています。Iterator はデータセット内の現在の位置を維持し、テンソルのタプルとして次の要素にアクセスする方法を提供します。

iteratorメソッドを呼び出すことによってデータセットからIteratorを作ることができます。ここにはいくつかのオプションがあります。

単純なケースでは、1回のみのイテレータがうまく機能します。自動的に初期化され、データを1回通過させることができます。これは、基本的にキューから取得できる機能を提供します。

より高度なオプションは、初期化可能なイテレータで、複数のデータソース間の切り替えなど、より洗練された使い方を提供しています...

..主な違いは、初期化可能なイテレータは、初期化のために実行できるオペレーションを与えることができます。
・複数回実行可能
で
・異なるファイルリストや異なるエポック数などのようなパラメータを実行時にfeed可能です。

イテレータを設定したら、 get_next() メソッドを使用してイテレータから次の要素にアクセスできます。 これは古典的な TensorFlow で、遅延実行があるため、session.run に渡して次の要素を生成する必要があります。

実際にどうやって使うのでしょうか?
ここで、画像とラベルのバッチのデータセットがあるとします。
イテレータを作成し、get_nextの結果をあなたのモデルと最適化機能を使って訓練を行い、その訓練をループで実行します。
OutOfRangeErrorは、ファイルの終わりに対する私たちの魅力的な名前です。
この定型文をすべてあなた自身で書く必要はないことに注意してください...

たとえば、Estimator APIを使用している場合は、最初の数行を入力関数にラップするだけで、Estimatorがループ処理を行います。

キューではできないこともあなたに味わっていただきたいと思います。
(1エポックと呼んでいる単位の)データを正確に一通り実行し、次を開始する前に幾つかの エポック終了時の計算(end-of-epoch computation) を実行するとしましょう。
古いキューベースのAPIでは、基本的に単一のグローバルなone-shot(1回だけの) iterator があるため、これをやりたい場合はsessionを解体して再起動する必要があります。これは不器用で処理も遅くなります。
このスライドでは、初期化可能なイテレータがその問題をどのように解決するかを示しています。このように、エポックを越えて外側のループを持つことができます。そのループの始めにイテレータを初期化し、範囲外になるまで訓練し、最後にエポックの計算を行い、パイプラインを再起動します。
エポック終了時の計算では、検証のために別のデータセットを反復処理する必要があるかもしれません。あるいは、イニシャライザをパラメータ化して、各エポックで異なる処理を行うこともできます。

tf.data APIをまとめましょう。
ここでは、学ぶべき2つの新しいクラスがありました。
tf.data.Dataset では、データソースと機能変換の構成としての入力パイプラインを表しました。
また、tf.data.Iteratorを使用すると、データセットから要素にシーケンシャル(順番)にアクセスすることができました。
うまくいけば、既存のAPIよりシンプルであると確信しています。
tf.data の柔軟性は次の2つの点からもたらされます:
・複雑なパイプラインを構築するために一緒に構成された豊富な変換セット
と
・同じプログラム内に複数のデータセットとイテレータを作成できるため、振る舞いをパラメータ化してさまざまなソース間を切り替えることが可能
なことです。

パフォーマンスについても少し語りたいとおもいます。
ここでの努力に対する全ての目的は、使いやすく高速なものを作ることにあります。

あなたがこれまでずっと feed_dict ベースのプログラミングをしてきているのであれば、かなりのスピードアップを期待できるでしょう。
実装されている内容を詳しく説明する時間はありませんが、主な性能向上ポイントとしては、Pythonのオーバーヘッドを避けるために C++ で tf.data を実装しているところにあります。
tf.data パイプラインを同等のキューベースのパイプラインと比較すると、同様の構造のキューとスレッドが使用されますが、クリティカルパスには Python キューランナースレッドが存在しないため、tf.data パイプラインは グローバルインタープリタロックによって制限され、より高いスループットにエンハンスされます。

ただし、現在の実装は、デフォルトでは決定論的(確定的)、順次および同期的です。 すべてのステージのバッファとスレッドを作成し、要素を生成するために競合するキューベースのAPIとは異なり、並列性と非決定性のオプトインを行うという控えめなアプローチをとってきました。 その理由の1つは、トレーニングモデルのRAM要件が非常に大きくなる可能性があるということです。1つのバッチはマルチGPUイメージモデルでは数百MBから数ギガバイトになる可能性があり、コンピュータのスラッシングを開始するよりも遅く予測可能です。
幸いにも、我々はより高いパフォーマンスの選択を容易にしました...
このデータセットのサンプルを見て、パフォーマンス関連のコードを入れようとしている不審なスペースをつかって再編成してみしましょう!
私は努力順で行くつもりです...

まず、非同期パイプラインを有効にし、dataset.prefetch() でこれを行うことができます。これは本質的に恒等変換ですが、バックグラウンドスレッドとバインドされたバッファを作成して要素をプリフェッチします。
残りのパイプラインのコストが安い場合は、現在のバッチのトレーニングと次のバッチの事前処理を重複させることができます。

事前処理がより大変な場合は、並列化したくなるかもしれません。
これは、 num_parallel_calls を dataset.map() に追加するだけで簡単にできます。
今度は、TensorFlowスレッドプールを使用して一度に64レコードを解析します。

最後の方法は、GCSのような分散ファイルシステムを使ってデータを保存する場合に最も便利です。
ファイルベースのデータセットでは、一度に1つのファイルが読み込まれるため、ほとんどの時間を I/O のブロックに費やす可能性があります。
この小さなインターリーブとプリフェッチガジェットを使用すると、8つのファイルを同時に読み込み、バッファを保持してレイテンシの変動を隠すことができます。

さて、ここまで新しい tf.data API を紹介してきました。
セッションの終盤は、今後何が起こっていくのかを知りたいだけだとおもいます。
私はすでに、TensorFlow 1.4 において API が tf.dataに移動していると述べました。
これのバージョンから、後方互換性の保証をしていきます。みなさんのプロダクトではそれに頼ることをお勧めします。

我々の次の大きな目標は、GPUメモリへの自動ステージングを可能にすることです。 これはパフォーマンスにとって重要です。プログラムの1行の変更でこれを有効にする必要があります。

そして長期的には、自動パフォーマンス最適化のチャンスに興味があります。 私は既に静的最適化に関する豊富な文献があると述べましたが、新しいAPIは、実行時にバッファサイズ、スレッド数、プレースメントを設定する興味深い可能性を与えてくれますし、これらを最適化するLearning2Learnや強化学習のテクニックのような事さえ使うでしょう。

このセッションでは、TensorFlow内へのデータ取得は苦痛を伴うものではないことを示しました。
tf.data はシンプルですが、高速で、柔軟性があり、以前はできなかったあらゆることを行うことができます。
あなたがそれを使って構築することを聞くのが待ちきれません。
ああ。 また、私たちが公開したばかりの基礎を紹介するブログポストもあります...
聞いてくれてありがとう、質問をいただけると嬉しいのですが..

-------
..多分ノート部分は、
Youtubeの自動テロップ機能の出ててきた英語をそのままではなく
直しているのだとおもうのだけど、
ところどころ..ああ、ここ、ドヤ顔してるな..きっと..というのが
よめる英語だった..
実装のスードコードが載っていたので
非常によくわかった。
キューっていうモノがあるのは
本家サイトを翻訳していたときから知ってはいたんだけど、
(もちろん非同期の基本モデルの登場人物だってことも)
これまでは「まずは動作させること」に命を燃やしていたので
feed_dict 経由一本槍だった..
..たしかに feed_dict で投入する段階って、
TensorFlow の C++ の実装との境界レベルだともうので
そこまでずーっとシングルスレッド一本で書いてたら
遅くなるよなあ..
..入力層にデータを入れるところからが
機械学習と思っているほかのライブラリと違って、
TensorFlowは
データ入力するところ(事前処理)も機械学習ですって
いっているわけね。
バッチ毎回の豆乳までにその分のデータを用意すりゃいいでしょ
っていうことで遅延リストを使うあたり
DBアクセスのHibernateっぽい..
やっぱコンピュータは I/O がボトルネックになるのは
基本中の基本ということか..
にしても.. バッチ1回毎に学習データに変化を持たせる..
..域まで機械学習こなしてないなあ..
..最先端の機械学習屋はそんなこともやってるんだ..
p.s.
そうか..
これからしばらくは、
Qiitaとかに出してるTensorFlowサンプルコードや
人の書いたコードとかの
session を withしてるなかで
feed_dictをつかっていたら
「まだまだ、わかってないね、チミ(シー、シー)」
とか言えば、
TensorFlowなんちゃって玄人
にすぐなれるってことか..
..もちろん、
この記事を読んでいる人は
みないい人たちだから
そんなことしませんよね...

0 件のコメント:
コメントを投稿